
B60 和 B50 用的是同一顆 Battlemage G21 晶片,media engine 一樣,SR-IOV 支援一樣,差別就是 VRAM:B60 24GB,B50 16GB。這個差距在某些工作上其實蠻具體的,在某些工作上又幾乎感覺不到。
兩張卡都在同一台 host 上跑,所以比較數字反映的是卡本身的差異,不是平台造成的。
Table of Contents
測試平台
- Host OS: Proxmox VE,Debian GNU/Linux 13 (trixie),kernel
6.17.13-2-pve - CPU: AMD EPYC 平台(雙插槽)
- RAM: 128GB ECC
- Driver stack:
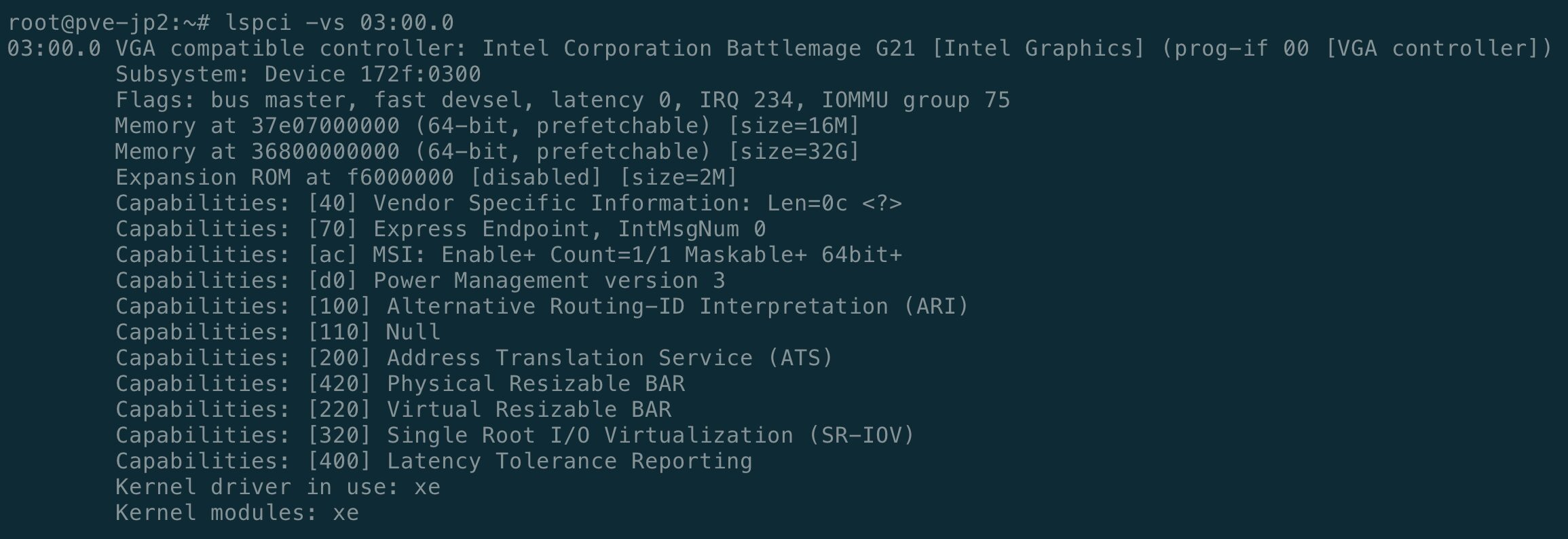
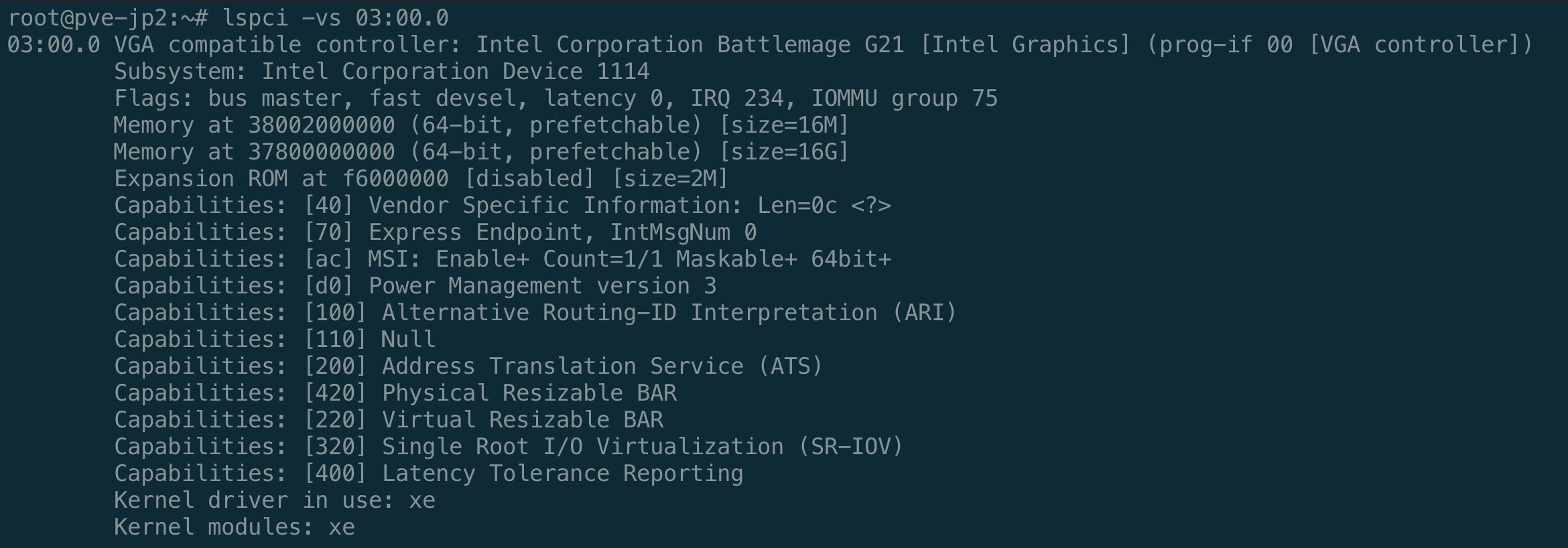
xe - B60: Intel Arc Pro B60 24GB(PCI ID
8086:e211,sriov_totalvfs=7) - B50: Intel Arc Pro B50 16GB(PCI ID
8086:e212,sriov_totalvfs=2) - Container images:
vllm-xpu-env(vLLM 0.17.2.dev,本地自建)、linuxserver/ffmpeg:latest - 虛擬化目標: Ubuntu 24.04 cloud-init VM,HWE kernel
6.17.0-19-generic
B60 待機: 整卡功耗約 32W(ASPM L1 啟用,無負載)——GPU die package 本身約 19W,其餘約 13W 來自 VRAM 和 VRM。B50 待機: 平均 20.3W(整卡)。
LLM 推理:整卡模式
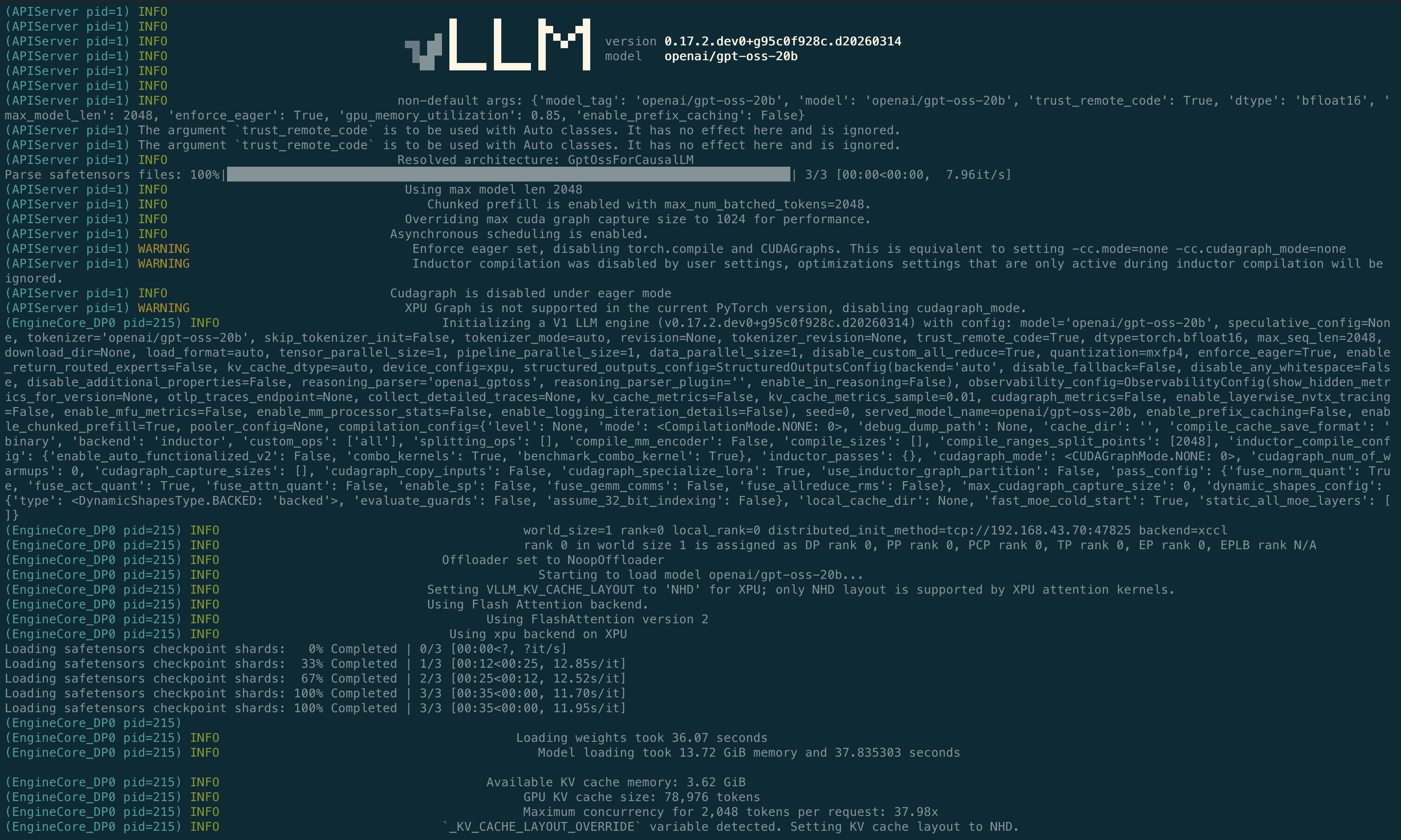
測試模型是 openai/gpt-oss-20b。20B 參數模型用 BF16 需要約 40GB——vLLM XPU stack 會自動對這個模型套用 mxfp4 量化,把權重壓到 13.72 GiB。
vllm-xpu-env 的 entrypoint 是 vllm serve,模型名稱和參數直接帶在後面。不想自己 build 的話,Intel 的預建 image intel/vllm:0.14.1-xpu 可以直接替換,參數完全一樣。Model weights 掛載自 /var/lib/docker,一方面是 root disk 空間有限,另一方面是讓不同 container 可以共用已下載的模型。
這個 stack 上有兩個參數兩張卡都不能省:
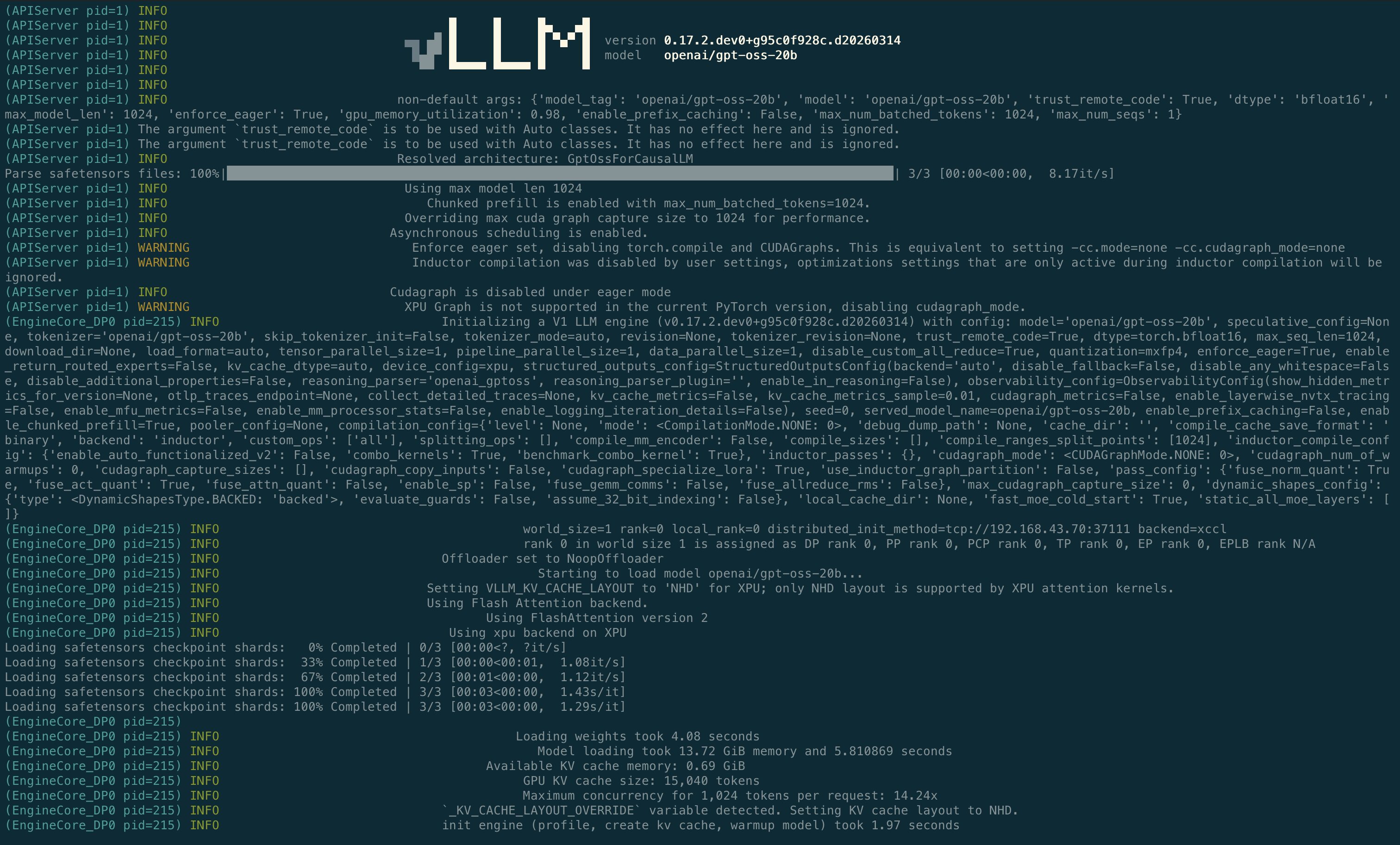
--enforce-eager:vLLM 預設的 graph mode 會預錄 GPU 操作成可 replay 的 graph,省下 inference overhead,但代價是要額外分配一塊 VRAM 給 graph buffer。對已經快把 VRAM 塞滿的大模型來說,這塊多出來的分配就足以觸發 OOM。Eager mode 跳過 graph capture,每個操作直接執行,吞吐量大約少 3–7%,但至少模型裝得進去。--gpu-memory-utilization:B60 設 0.85 就有足夠餘裕。B50 則是硬性需求 0.98——PyTorch 看到的可用記憶體是 15.126 GiB,模型吃掉 13.72 GiB,只剩 0.69 GiB 給 KV cache。設 0.85 直接失敗,allocator 需要 1.28 GiB 但根本不夠。
B60 指令:
docker run --rm -it --name b60-vllm --shm-size 10g \
--net=host --ipc=host --privileged \
--device /dev/dri:/dev/dri \
-v /var/lib/docker/hf-cache:/root/.cache/huggingface \
-v /var/lib/docker/models:/models \
-e HF_HOME=/root/.cache/huggingface \
-e HUGGINGFACE_HUB_CACHE=/root/.cache/huggingface/hub \
vllm-xpu-env \
openai/gpt-oss-20b \
--dtype bfloat16 \
--max-model-len 2048 \
--enforce-eager \
--trust-remote-code \
--gpu-memory-util=0.85 \
--no-enable-prefix-cachingB50 指令(同一個 image 和 volume 掛載,記憶體參數設得更緊):
docker run --rm -it --name b50-vllm --shm-size 10g \
--net=host --ipc=host --privileged \
--device /dev/dri:/dev/dri \
-v /var/lib/docker/hf-cache:/root/.cache/huggingface \
-v /var/lib/docker/models:/models \
-e HF_HOME=/root/.cache/huggingface \
-e HUGGINGFACE_HUB_CACHE=/root/.cache/huggingface/hub \
vllm-xpu-env \
openai/gpt-oss-20b \
--dtype bfloat16 \
--max-model-len 1024 \
--max-num-seqs 1 \
--max-num-batched-tokens 1024 \
--gpu-memory-utilization 0.98 \
--enforce-eager \
--trust-remote-code \
--no-enable-prefix-caching結果
Benchmark 參數:64 個 prompt,384 input / 192 output token,concurrency 1。
| 指標 | B60(24GB) | B50(16GB) |
|---|---|---|
| 成功 request | 64/64 | 64/64 |
| Output 吞吐量 | 39.78 tok/s | 36.26 tok/s |
| Mean TTFT | 101.56 ms | 171.85 ms |
| Median TTFT | 101.19 ms | 170.62 ms |
| P99 TTFT | 113.21 ms | 194.31 ms |
| Mean TPOT | 24.73 ms | 26.82 ms |
| 平均功耗(c=1) | 70.34 W | 67.96 W |
吞吐量的差距其實不大——39.78 vs 36.26 tok/s。真正說明問題的是 TTFT:B50 的 171ms 比 B60 的 101ms 高了 69%。原因不是算力,兩張卡跑的是同樣的 mxfp4 量化權重——差別是 KV cache 空間。B50 只剩 0.69 GiB 給 KV cache,連在 concurrency 1 的情況下 prefill 都幾乎沒有餘裕。
B50 的 64 個 request 都順利跑完了。但真的沒有空間了——換個稍長的 context、換條量化路徑、或是模型再大一點,都可能讓它直接載入失敗。
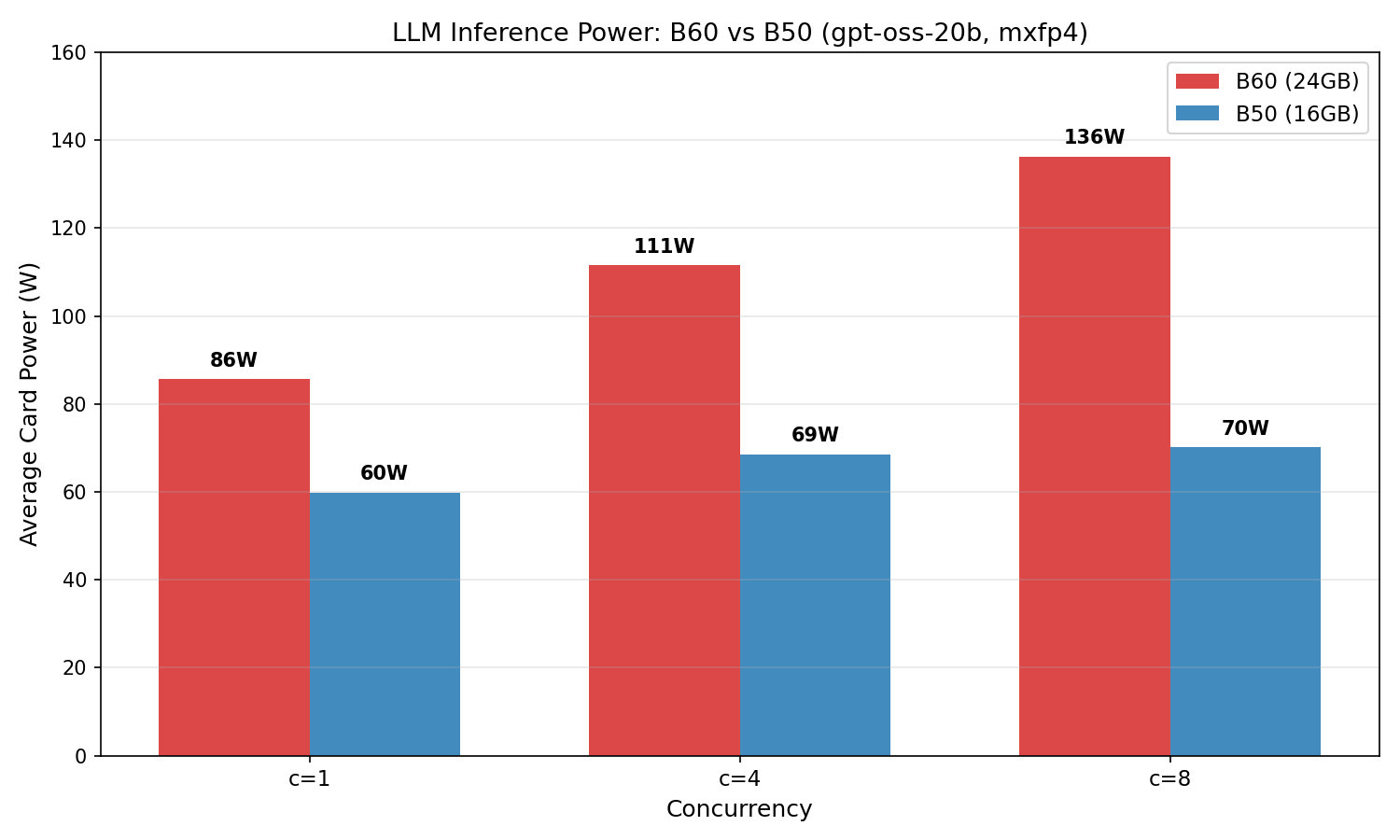
功耗在 concurrency 1 兩張卡差不多,都在 70W 左右。差距在拉高 concurrency 之後才出來:
| Concurrency | B60 tok/s | B60 TTFT (ms) | B60 功耗 | B50 tok/s | B50 TTFT (ms) | B50 功耗 |
|---|---|---|---|---|---|---|
| 1 | 39.78 | 102 | ~70 W | 35.85 | 172 | ~70 W |
| 4 | 145 | 367 | ~122 W | 105 | 489 | ~70 W |
| 8 | 271 | 685 | ~122 W | 168 | 755 | ~70 W |
B60 從 70W 拉到平均 122W(峰值 155W),吞吐量一路爬到 concurrency 8 的 271 tok/s。B50 不管 concurrency 多高,功耗都鎖在 ~70W——吞吐量還是會隨 concurrency 往上走(c=8 時 168 tok/s,大約是 B60 的 62%),但卡本身始終不多吃電。這個比例跟兩張卡的 compute core 數量差距蠻吻合的。
兩張卡都是算力先到瓶頸,不是散熱。所有 concurrency 都沒有 failed request。
Media
兩張卡用的是同一組 dedicated video engine,QSV encode、decode、transcode 的路徑一樣。測試環境跑在 Docker 裡,涵蓋兩個真實 4K 片源(Big Buck Bunny 4K60、Sintel 4K)和三個合成 pattern(testsrc2、smptebars、noise)。
關於 QSV init 路徑: container 裡初始化 QSV 有兩種方式。vaapi→qsv chain(-init_hw_device vaapi=va:/dev/dri/renderD128 -init_hw_device qsv=qsv@va)先過 VA-API 層——Jellyfin 預設走的就是這條。另一種是 MFX 直接路徑(-init_hw_device qsv=qsv:MFX_IMPL_hw),跳過 VA-API 直接跟 oneVPL runtime 溝通。兩條路徑底下用的是同一顆 hardware encoder,但 MFX 路徑的 init overhead 比較低。本文各測試使用的 init path 如下:
- 效能與功耗表格和並行 Transcode 表格:
-hwaccel qsv搭配硬體解碼和編碼,透過linuxserver/ffmpeg——全 GPU 加速 pipeline,跟 Jellyfin 預設路徑一致。 - HEVC Noise 重複性測試:MFX 直接路徑,配
linuxserver/ffmpeg。 - VF Media 比較:
-hwaccel qsv搭配硬體解碼和編碼,透過linuxserver/ffmpeg——跟效能表格一樣的 pipeline,PF 和 VF 用同一個 container。
兩種 init path 的數字不能直接互比。
另外一個要注意的點:兩張 Battlemage 卡用的 xe kernel driver,在 guest VM 裡面不被 QSV/oneVPL runtime 認。VM 的 stock ffmpeg 用 QSV hwaccel 會報 "non-matching kernel driver (xe)" 錯誤。Docker container 裡的 bundled iHD driver 可以用是因為它走 VA-API,而 VA-API 支援 xe。這是 userspace 相容性的問題,不是硬體限制。
效能與功耗
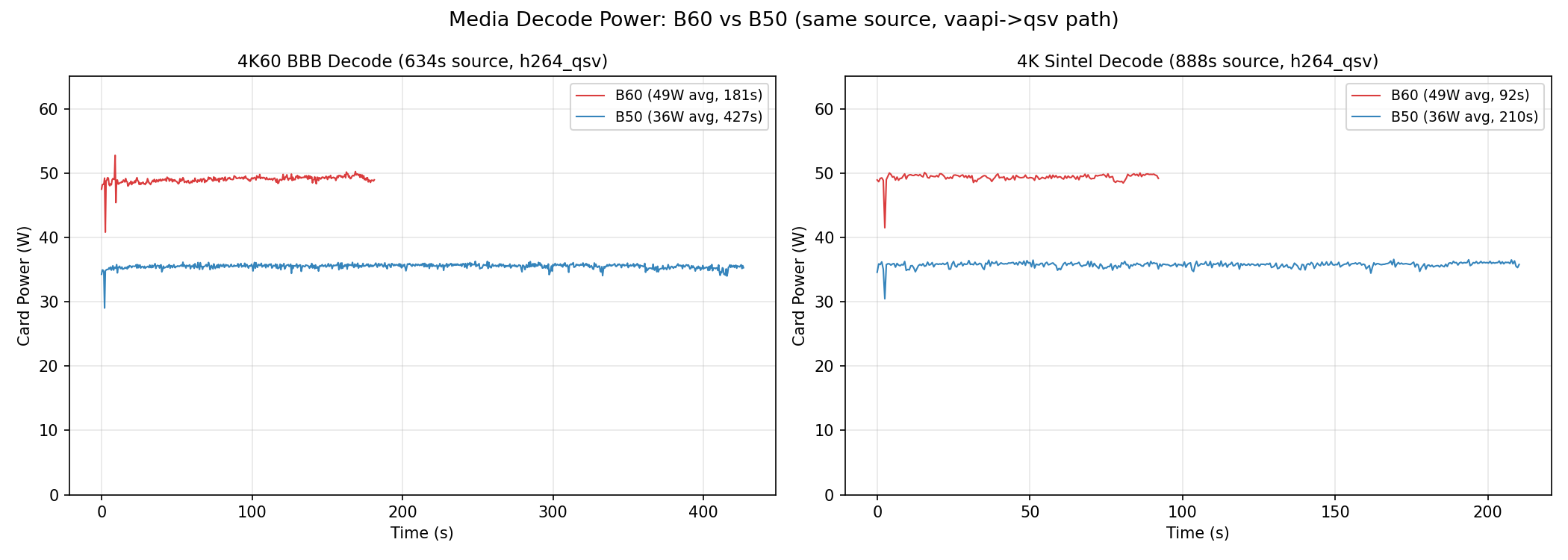
| 情境 | B60 W | B60 FPS | B50 W | B50 FPS |
|---|---|---|---|---|
| 4K60 BBB decode | 49.0 | 208(3.5x) | 35.7 | 196(3.3x) |
| 4K60 Sintel decode | 49.3 | 228(9.5x) | 36.3 | 217(9.1x) |
| testsrc2 H.264 encode | 53.2 | 192(3.2x) | 38.9 | 191(3.2x) |
| testsrc2 HEVC encode | 53.5 | 203(3.4x) | 38.8 | 192(3.2x) |
| testsrc2 AV1 encode | 53.0 | 203(3.4x) | 38.6 | 191(3.2x) |
| BBB 4K→1080p transcode | 53.5 | 209(3.5x) | 38.6 | 197(3.3x) |
效能幾乎一樣——兩張卡共用同一顆 media engine,數字也反映了這點。B60 在任何單一測試最多只快 6%,在 run-to-run 變異範圍內。真正的差別是功耗:B60 在每個場景多吃 14–15W。兩張卡的待機功耗差距本身就有約 12W(32W vs 20W),所以大部分差距來自板卡本身的基礎開銷(VRAM、VRM),不是 video engine 造成的。
VMAF 畫質
testsrc2(均衡合成片段)的 VMAF(兩張卡用同一顆 hardware encoder,分數一樣):
| Codec | VMAF |
|---|---|
| H.264 | 85.20 |
| HEVC | 85.23 |
| AV1 | 83.46 |
smptebars(簡單片段):兩張卡三個 codec 都在 97.4 左右。noise(不可壓縮極限測試):H.264 17.5–17.7、HEVC 13.7–14.9、AV1 16.4——固定 bitrate 對不可壓縮內容做 encode,VMAF 崩掉是預期內的結果。
HEVC noise encode 原本是 B60 的一個 edge case——ReBAR 之前跑五次重複測試,五次都在約 55 秒後以 exit code 183 crash。ReBAR BIOS mod 之後,B60 順利通過(5/5,~40 fps),跟 B50 一致(5/5,~40 fps)。crash 的原因是 small-BAR memory configuration,不是 firmware bug。兩張卡的 H.264 和 AV1 noise encode 都正常完成。
並行 Transcode
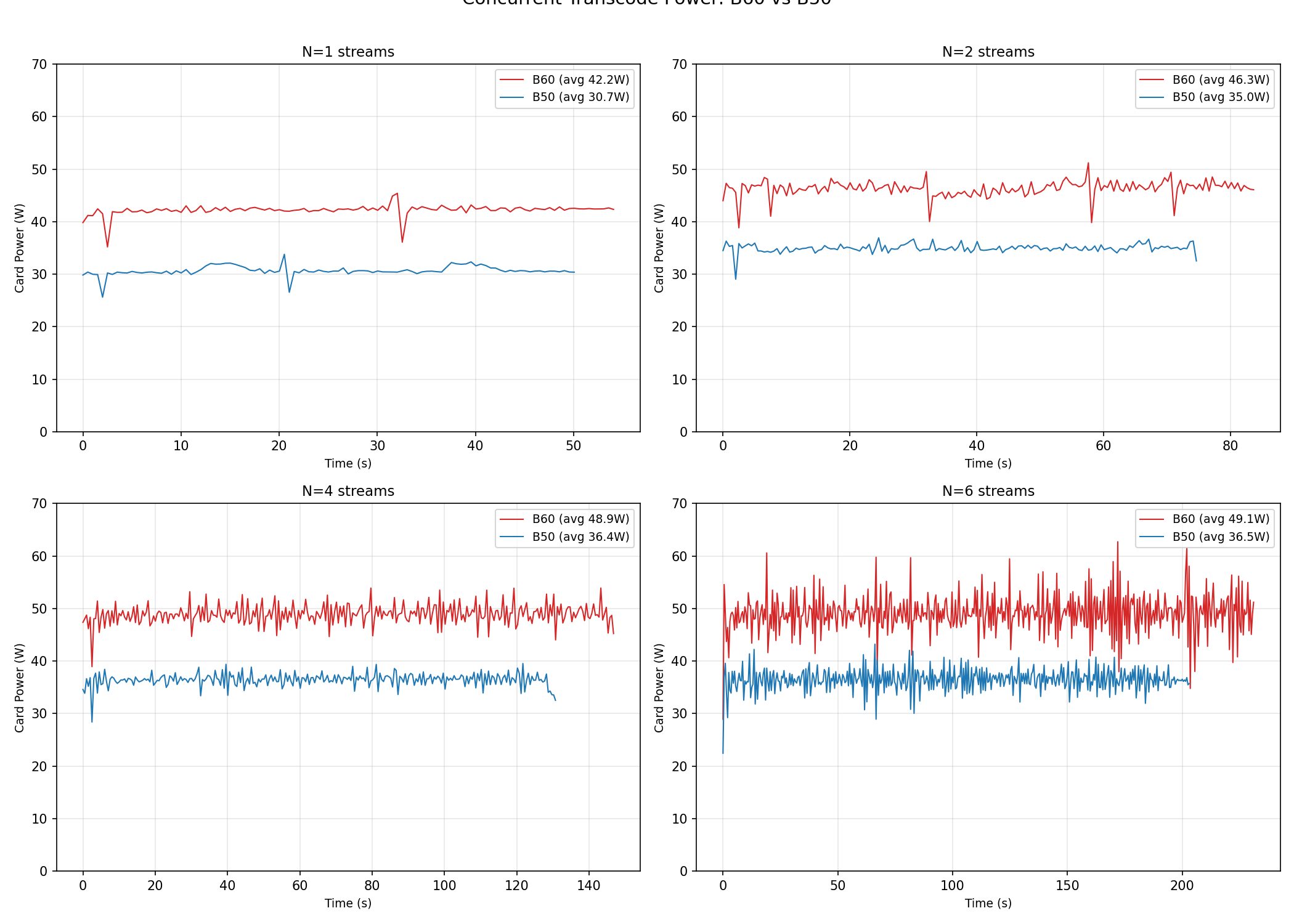
| 串流數 | B60 FPS | B60 功耗 (W) | B50 FPS | B50 功耗 (W) |
|---|---|---|---|---|
| 1 | 196 | 50.4 | 187 | 37.9 |
| 2 | 164 | 53.7 | 159 | 40.6 |
| 3 | 114 | 54.9 | 110 | 41.1 |
| 4 | 86 | 55.2 | 83 | 41.3 |
| 6 | 57 | 55.3 | 55 | 41.4 |
兩張卡都能同時跑 5 路 4K→1080p HEVC transcode 還不掉到即時以下。效能幾乎一樣——每個串流數大約差 5%,和單串流的結果一致。瓶頸在共用的 media engine,不在功耗預算。功耗的故事也跟其他測試一樣:B60 在每個級別多吃 13–15W,換來的是幾乎相同的吞吐量。
這條 pipeline 用的是 -hwaccel qsv,搭配硬體解碼(h264_qsv)和硬體編碼(hevc_qsv),透過 linuxserver/ffmpeg——全 GPU 加速,不走 CPU 解碼。
SR-IOV
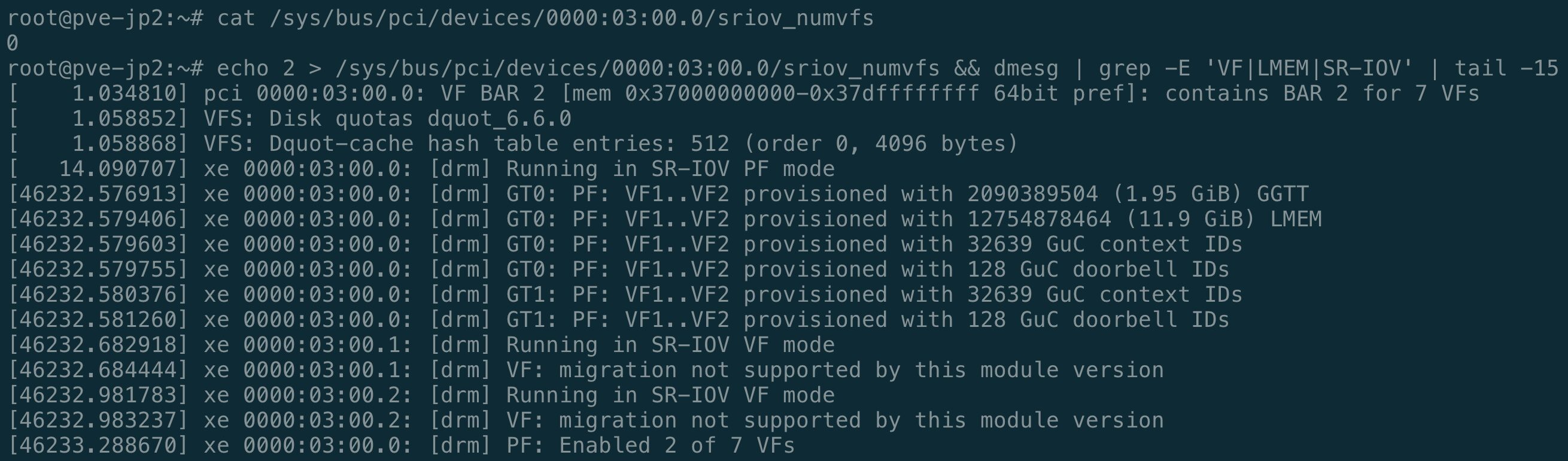
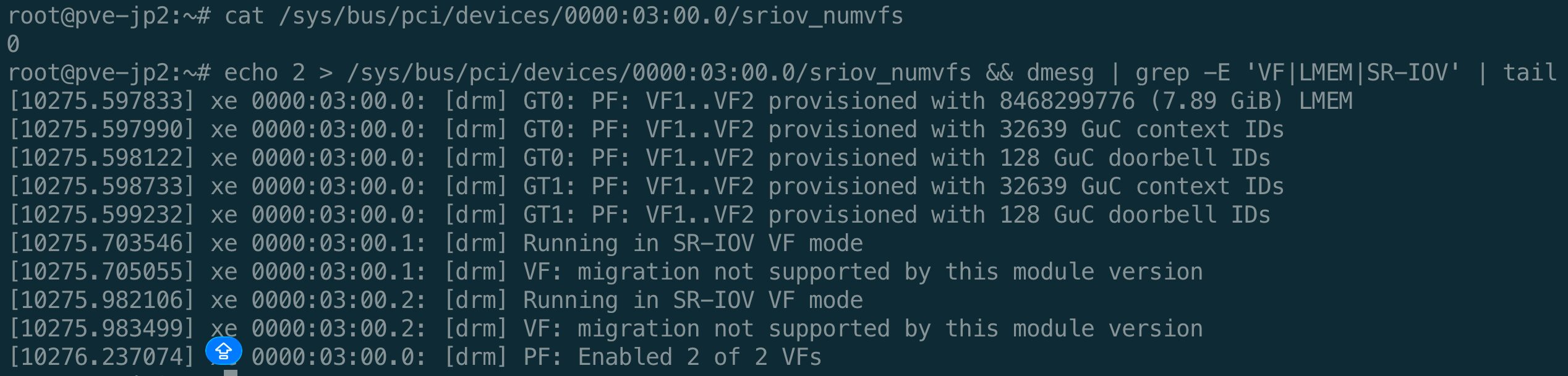
兩張卡都透過 xe driver 支援 SR-IOV。要讓 VF passthrough 能用,這個平台需要在 kernel boot 參數裡加兩個東西——不管裝的是哪張卡,兩個應該都要加:
pcie_acs_override=downstream,multifunction pci=realloc,nocrspcie_acs_override:VF 和 PF 預設會被放在同一個 IOMMU group,沒辦法分開 passthrough。這個參數覆蓋 BIOS 的 ACS 設定,讓平台把 PF 和 VF 分到不同的 group。pci=realloc,nocrs:BIOS 分配的 PCIe bridge window 剛好只夠放 PF 的 BAR,沒有空間給 VF 的 MMIO BAR。nocrs讓 kernel 在 boot 時可以無視 BIOS 的這個限制;只加pci=realloc是不夠的。
把兩個都加進 GRUB_CMDLINE_LINUX_DEFAULT 再重開機。
沒有 ReBAR 的伺服器平台:xe.vram_bar_size workaround
在 Dell R7515 伺服器上,設定方式跟上面的桌面平台不同。R7515 不支援 Resizable BAR,Dell 的 BIOS 有加密,無法用 ReBarUEFI 去 patch,除非用 programmer 直接讀取 BIOS 晶片的資料。
桌面平台的兩個參數在這裡行為不同:
pci=nocrs:R7515 加了會在開機時卡住,不能用。pci=realloc單獨加沒問題,應該保留。pcie_acs_override:不需要;R7515 本身就會把 VF 放到獨立的 IOMMU group。
即使伺服器的 physical PCIe BAR 夠大,VF 建立還是失敗了。解法是加一個 kernel module 參數:
xe.vram_bar_size=256pci=big_root_window 是先加的,但單獨加不夠用。真正解決問題的是 xe.vram_bar_size=256。數值本身也有差:試過 512 一樣失敗,256 才是有效的值。
numvfs=2 時各 VF 拿到的 LMEM:
| 卡 | 最多 VF 數 | 每 VF LMEM(numvfs=2) |
|---|---|---|
| B60 | 7 | ~11.3 GiB |
| B50 | 2 | ~7.89 GiB |
B60 只要啟用任何 VF,PF 在 model stack 看起來就不再像一張完整的卡,整卡 gpt-oss-20b 推理就跑不動了。整卡模式和 VF 分割是互斥的,開機前要先決定好。
Guest OS 注意事項: Ubuntu 24.04 內建的 media stack 不夠應付 VF 的 media 路徑。升級到 Intel 較新的 Ubuntu graphics stack 之後,VF 裡的 media 測試才能正常運作。
VF 推理
兩張卡都設 numvfs=2,把 VF1 passthrough 進 Ubuntu 24.04 VM,在裡面用同一個 vllm-xpu-env image 跑 Qwen3 benchmark(40 個 prompt,256 input / 128 output token)。
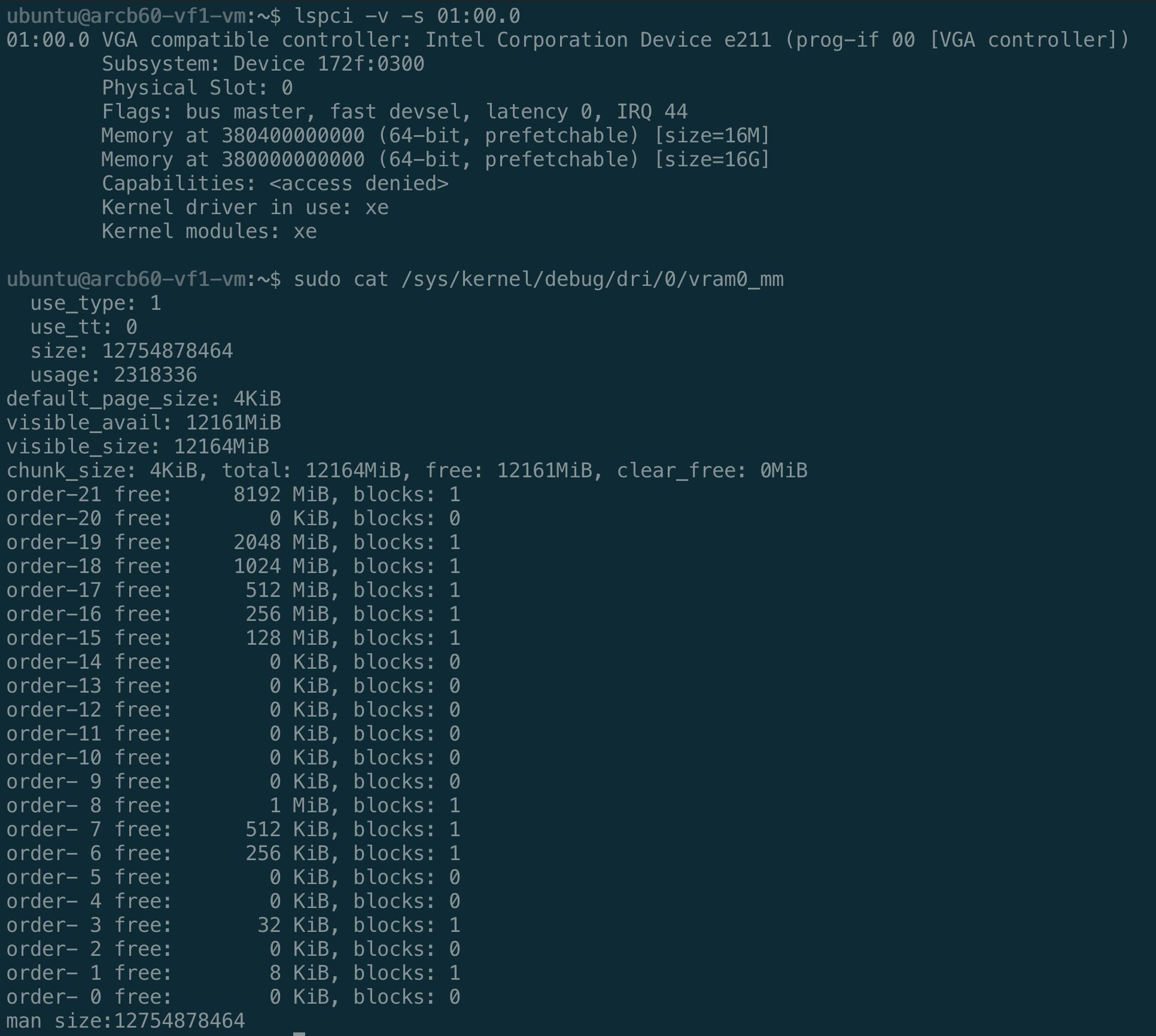
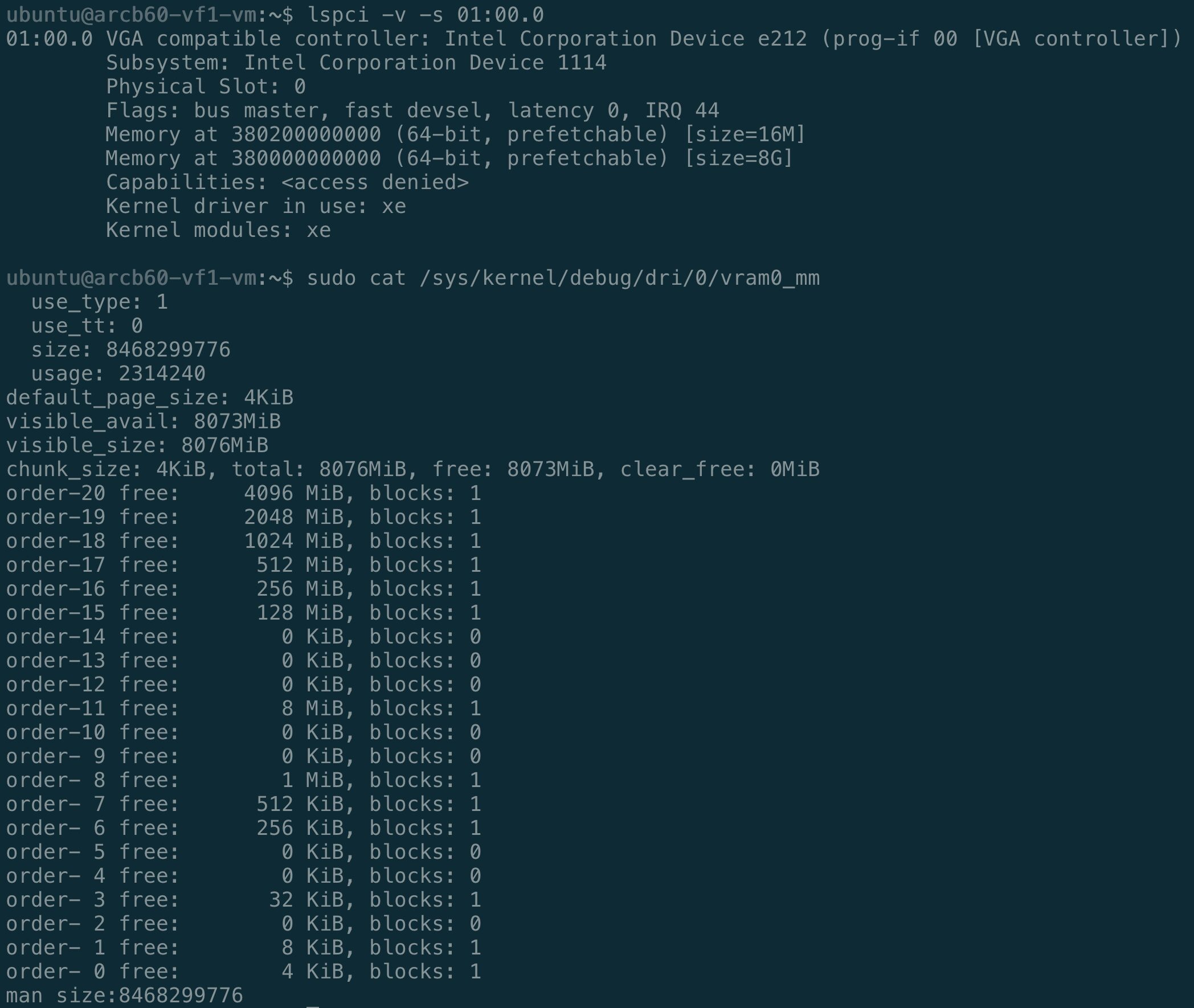
| 模型 | 卡 | Concurrency | Output tok/s | Median TTFT (ms) | TPOT (ms) |
|---|---|---|---|---|---|
| Qwen3-0.6B | B60 VF | 1 | 32.75 | 67.2 | 30.2 |
| Qwen3-0.6B | B60 VF | 4 | 134.05 | 98.5 | 29.3 |
| Qwen3-0.6B | B50 VF | 1 | 31.9 | 93.8 | 30.6 |
| Qwen3-0.6B | B50 VF | 4 | 130.4 | 98.7 | 30.0 |
| Qwen3-1.7B | B60 VF | 1 | 32.09 | 69.6 | 30.8 |
| Qwen3-1.7B | B60 VF | 4 | 125.74 | 106.4 | 31.2 |
| Qwen3-1.7B | B50 VF | 1 | 32.2 | 68.8 | 30.5 |
| Qwen3-1.7B | B50 VF | 4 | 125.9 | 117.7 | 30.2 |
| Qwen3-4B | B60 VF | 1 | 24.21 | 117.5 | 40.7 |
| Qwen3-4B | B60 VF | 4 | 95.28 | 150.7 | 41.2 |
| Qwen3-4B | B50 VF | — | OOM | — | — |
0.6B 和 1.7B 在兩張卡上的數字其實蠻接近的——TPOT 都維持在 ~30ms,concurrency 4 的吞吐量都在 125–134 tok/s。LMEM 大小在這邊不是瓶頸,compute slice 才是。
4B 才是兩張卡真正分岔的地方。Qwen3-4B 用 BF16 需要約 7.7 GiB 的權重。放進 B60 的 11.3 GiB VF 還夠(加上 --gpu-memory-utilization 0.95 --max-model-len 2048),放進 B50 的 7.89 GiB VF 就直接 OOM。B60 VF 跑 4B 的 TPOT 升到 ~41ms,比跑小模型慢——較大的模型讓這個 VF slice 在更低的 token rate 就跑滿了。
B50 VF 的上限: vllm XPU build 支援原生 BF16/FP16 和 auto-mxfp4(針對特定模型,如 gpt-oss-20b)。AWQ 和 GGUF 的 kernel 沒有,量化後的大模型不是可行的 workaround。Qwen3-1.7B 是 B50 VF 上測試成功的最大 Qwen3 模型。
B60 VF 推理整段測試的功耗(涵蓋三個模型,host 側 telemetry):平均 54.1W,峰值 100.6W。穩定待機(整卡、無 VF、ASPM L1):約 32W 整卡功耗。
VF media 參考數據: VF passthrough 在兩張卡上的 overhead 都可以忽略。用同樣的 -hwaccel qsv pipeline 在 PF 和 VF 上跑(H.264 decode → H.264/HEVC/AV1 encode,4K60,同一個 container):B60 VF 的 H.264 達到 PF 的 99%,HEVC 和 AV1 都是 89%。B50 搭載同一顆 G21 media engine 和同樣的 VF 硬體切割機制,結果一致。HEVC 和 AV1 的那 11% 差距來自較複雜 codec path 的 IOMMU overhead,不是 media engine 的問題。
結論
8GB VRAM 的差距在每個記憶體受限的工作上都是具體的,但在哪邊差最大,其實蠻明確的:
選 B60 的情況:
- 想跑 20B 等級的模型,而且 KV cache 要有足夠的空間(c=8 時 271 tok/s vs B50 的 168 tok/s)
- 需要兩個以上的 VF slice(B60 最多七個)
- VF 推理想跑到 4B 以上的模型(Qwen3-4B 在 B60 VF 上跑得動,B50 VF 直接 OOM)
- 高並行 media 場景需要略高的吞吐量(共用 media engine,最多快約 6%)
選 B50 的情況:
- 主要工作是 media 而且功耗效率很重要——各路徑功耗少 14–15W,同樣的吞吐量,同樣的 QSV 品質
- 兩個 VF 就夠用(一個 media VM、一個小型推理 server,剛好)
- VF 推理用 Qwen3-1.7B 以內的模型就足夠——這個尺寸兩張卡的效能幾乎一樣
- 整卡 LLM c=1 夠用就好——36 tok/s vs 40 tok/s,差距不大
兩張卡有共同的注意事項:guest 端的 Linux userspace 版本目前還是有差,而且要在一開始就決定跑整卡模式還是分割模式。ReBAR(Resizable BAR)強烈建議啟用——少了它,HEVC noise encode 會 crash,compute runtime 也可能初始化失敗。近幾年的消費級主機板通常在 BIOS 裡就有 ReBAR 開關可以直接打開。比較舊的伺服器主板(像這次用的 Supermicro H11SSL-i)沒有這個選項,需要手動用 ReBarDxe.ffs 修改 BIOS 韌體,門檻不低。如果你的平台不支援 ReBAR,基本的 media 工作可能還是能跑,但 compute 相關的工作負載可能會遇到問題。