 指標的解讀與應用")
目次
はじめに
CPU、メモリ、または I/O デバイスで競合が発生すると、ワークロードにレイテンシのスパイクやスループットの低下が生じ、OOM による強制終了のリスクに直面します。このような競合を正確に測定できない状況では、ユーザーはハードウェアリソースを保守的に運用するか、過剰な設定による頻繁な中断のリスクを冒すかのどちらかを強いられてきました。Linux カーネル 4.20 以降、PSI (Pressure Stall Information) という情報が追加され、リソース不足がシステム全体のパフォーマンスに与える影響をより正確に把握できるようになりました。本記事では、PSI の概要とその情報の読み解き方について簡単に紹介します。
概要
PSI は、リソース圧迫の増大を確認するための初めての標準的な手法を提供し、メモリ、CPU、IO という 3 つの主要なリソースに対して新しい圧迫指標を導入しました。
これらの圧迫指標を cgroup2 や他のカーネル空間・ユーザー空間のツールと組み合わせることで、リソース不足の兆候を検知し、不要なプロセスの停止や終了、システム内でのメモリの再割り当て、負荷の軽減、あるいはその他の対策を講じることが可能になります。
PSI 統計は早期警告装置のようなもので、リソース不足が迫っていることを知らせてくれます。これにより、リソースが枯渇し始める段階で、より積極的かつきめ細やかで、状況に応じた対策を講じることができます。
圧力指標インターフェース
各リソースの圧迫指標は、 /proc/pressure 内の対応するファイルから読み取ることができます。cpu、memory和io。
以下のコマンドを使用して、対応するリソースの圧迫指標を簡単に読み取ることができます。
$ cat /proc/pressure/resource_name出力形式は以下の通りです。
some avg10=0.42 avg60=0.18 avg300=0.14 total=2539018569
full avg10=0.00 avg60=0.00 avg300=0.00 total=0これには 2 つの指標が含まれています。some 和 fullと、それぞれの 10 秒、1 分、5 分間の平均値です。total はマイクロ秒単位で計算された合計時間です。
圧力指標(Pressure Metrics)の読み方
圧迫情報の読み取り方を理解した後は、それらの情報をどのように解釈すべきかを知る必要があります。
some
some リソース不足(例:メモリ不足)により、一部(1 つまたは複数)のタスクが遅延した時間の割合を示します。
下の図では、タスク A は遅延なく実行されていますが、タスク B はメモリを確保するために 30 秒待機する必要があり、その結果「some」の値が 50% になっています。
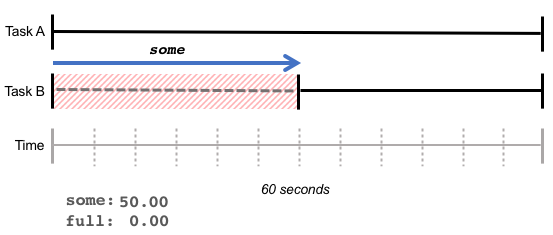
some リソース不足によって増加した遅延時間を表します。CPUが完了した総作業量は変わらないかもしれませんが、一部のタスクにより長い時間がかかっています。
full
full すべてのタスクがリソース不足のために遅延している時間の割合、つまり完全にアウトプットがない時間の量を表します。
以下の例では、タスクBがメモリを30秒間待機しています。この30秒間のうち、10秒間はタスクAも待機しています。これにより、 full 値は16.66%(10秒/60秒)となり、some 値は50.00%(30秒/60秒)となります。
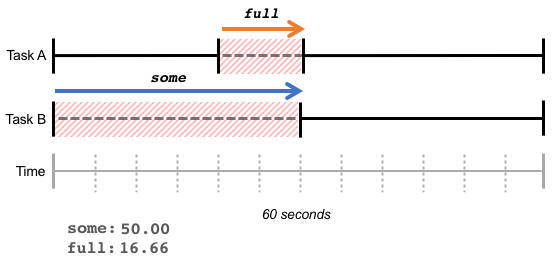
高 full 値は全体的なスループットの損失を表し、リソース不足により完了した総作業量が減少したことを示します。
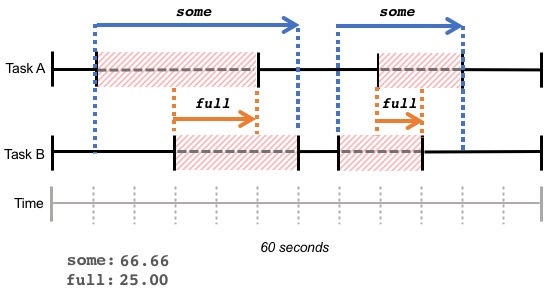
これらの統計データは、一定期間内にタスクが累積して待機した時間を反映していることに注意してください。待機時間が(上記の例のように)連続しているか、あるいは下図のように同じ期間内の断続的な待機時間の連続であるかは問いません。
PSIの監視
node_exporterを使用してシステムのPSIを監視できます。node_exporterはデフォルトでpressure collectorが有効になっており、以下の情報を取得できます。
- ノードCPUプレッシャー待機時間合計(秒)
- ノードI/Oプレッシャーストール時間合計(秒)
- ノードI/Oプレッシャー待機時間合計(秒)
- ノードメモリプレッシャーストール時間合計(秒)
- ノードメモリプレッシャー待機時間合計(秒)
まとめ
圧力指標(Pressure Metrics)は読み取りコストが低いため、最近の遅延をサンプリングしたり、特定のタスク操作の前後でサンプリングしてリソース関連の遅延時間を特定したりするのに役立ちます。ユーザーはこの指標を利用して、システム内で過度なリソース競合が発生していないかをより深く理解し、対処することができます。
参考文献
著作権表示:特に断りのない限り、本ブログのすべての記事はCC BY-NC-SA 4.0ライセンスの下で提供されています。

