
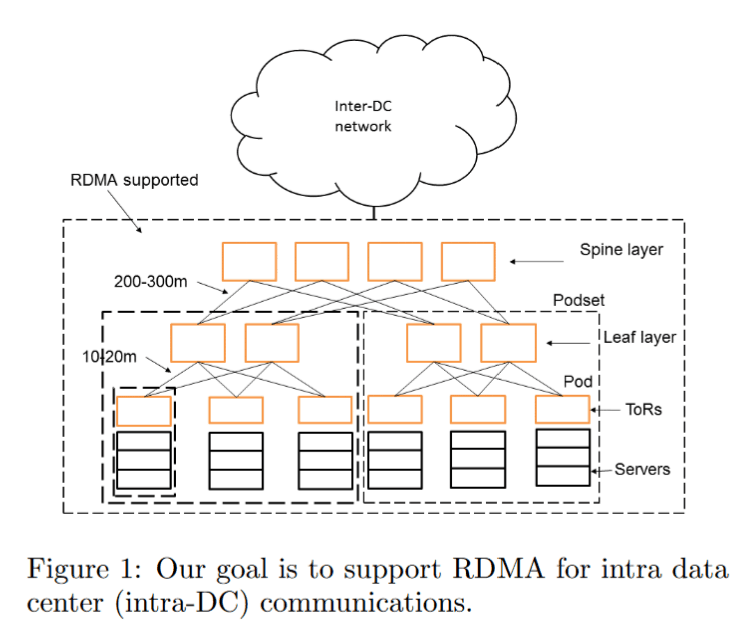
In the previous article RDMA Overview , I briefly introduced RDMA technology. This time, I will provide a brief guide to the paper Microsoft published at SIGCOMM 2016 regarding their large-scale deployment of RDMA in data centers RDMA over Commodity Ethernet at Scale as a simple overview.
Contents
Abstract
Over the past one and a half years, we have been using RDMA over commodity Ethernet (RoCEv2) to support some of Microsoft’s highly reliable, latency-sensitive services. This paper describes the challenges we encountered during the process and the solutions we devised to address them.
Essentially, this article introduces the challenges Microsoft encountered and the solutions they implemented while using RDMA in their infrastructure over the past year and a half.
In order to scale RoCEv2 beyond VLANs, we have designed a DSCP-based priority flow control (PFC) mechanism to ensure large-scale deployment.
To enable better scalability for RoCEv2, Microsoft designed DSCP-based PFC to accommodate large-scale deployments.
We have addressed the safety challenges brought by PFC-induced deadlock (yes, it happened!), RDMA transport livelock, and the NIC PFC pause frame storm problem. We have also built monitoring and management systems to ensure RDMA works as expected.
It describes some of the problems encountered due to PFC and Microsoft's solutions, while also detailing the design of a monitoring system.
Our experiences show that the safety and scalability issues of running RoCEv2 at scale can all be addressed, and RDMA can replace TCP for intra-data center communications to achieve low latency, low CPU overhead, and high throughput.
Microsoft's experience proves that the scalability and safety issues encountered with RoCEv2 can be resolved, and it can replace TCP as a low-latency, low-CPU-utilization, and high-bandwidth transmission method within data centers.
Introduction
With the rise of network services and the cloud in recent years, data center networks require increasingly high speeds and low latency. TCP/IP remains the primary transmission method within data centers today, but there are growing signs that TCP/IP is no longer sufficient to handle current demands. There are two main reasons for this:
- High CPU Utilization
- High Latency Caused by Kernel and Packet Drops
This paper summarizes the challenges Microsoft encountered while deploying RoCEv2 at scale and their solutions, including the following points:
- DSCP-based PFC to scale in Layer-3 (IP)
- RDMA Transport Livelock
- PFC Deadlock
- NIC PFC Pause Frame Storm
- Slow-receiver Symptom
DSCP-based PFC
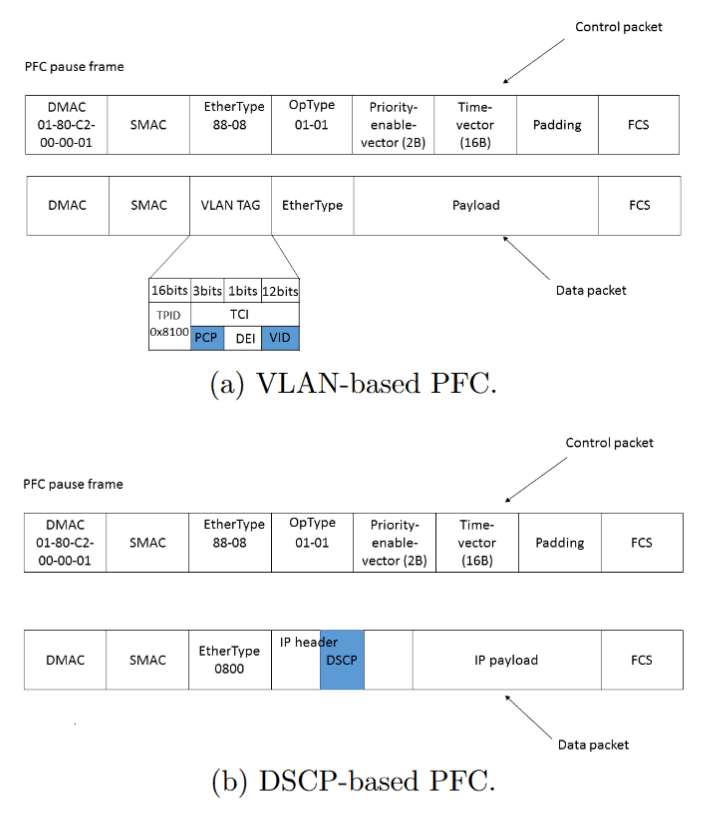 Traditional PFC implementations support PFC through the PCP (Priority Code Point) in the VLAN tag. However, Layer-2 VLANs cannot be used in data centers for two primary reasons.
Traditional PFC implementations support PFC through the PCP (Priority Code Point) in the VLAN tag. However, Layer-2 VLANs cannot be used in data centers for two primary reasons.
- The server is deployed via PXE. During PXE boot, the NIC is not configured with a VLAN, so it cannot receive packets with VLAN tags.
- The switch uses Layer-3 forwarding instead of Layer-2 bridging; Layer-3 networks offer better scalability, security, and are easier to monitor.
Fundamentally, PFC pause frames do not carry any VLAN tags, so the purpose of using VLANs is solely to carry packet priority information. Since DSCP in the IP header serves the same function, Microsoft developed a specification for PFC based on DSCP to resolve the two aforementioned issues.
Security Challenges
RDMA Transport Livelock
RDMA was fundamentally designed with the assumption that the network would not experience packet loss due to congestion. In RoCEv2, PFC is used to meet this condition; however, packet loss can still occur due to other factors such as FCS errors or hardware/software bugs. Microsoft aims to minimize the performance impact when such situations occur.
However, in practical testing, even an extremely low packet loss rate can cause RDMA applications to fail completely. This is because the retransmission algorithm used by NICs was "go-back-0," meaning that if any single packet is dropped within a message, the entire transmission restarts from the beginning.
Since complex mechanisms like TCP's SACK are difficult to implement in NICs, Microsoft collaborated with NIC vendors to implement a "go-back-N" algorithm. This also retransmits starting from the first dropped packet but significantly reduces the likelihood of livelocks.
PFC Deadlock
PFC Deadlock fundamentally occurs when there is a mismatch between the MAC Address Table and the ARP Table. In this scenario, the switch attempts to learn new MAC addresses through flooding. However, if PFC is enabled and a receiver is unable to accept packets, it can lead to a network-wide deadlock. This is a brief explanation; the paper provides a more detailed scenario analysis.
When a receiver malfunctions and cannot receive packets, the switch floods the packets to every port. This can cause congestion on other ports, triggering the transmission of PFC pause frames. These pause frames then propagate through the data center's leaf-spine network, resulting in a network-wide deadlock.
Microsoft's solution is to directly drop packets in a lossless network that lack a corresponding MAC address when a mismatch occurs between the MAC Address Table and the ARP Table. By avoiding flooding, they prevent other port buffers from being exhausted, thereby avoiding PFC deadlocks.
NIC PFC Pause Frame Storm
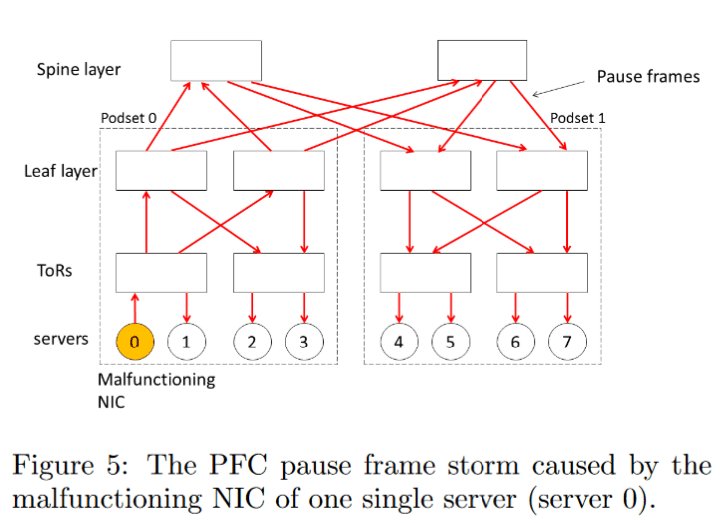 Microsoft observed that NICs might continuously send PFC pause frames under abnormal conditions. In the worst-case scenario, this leads to the following situation:
Microsoft observed that NICs might continuously send PFC pause frames under abnormal conditions. In the worst-case scenario, this leads to the following situation:
- An abnormal NIC continuously sends pause frames to the TOR switch.
- The TOR switch consequently pauses all traffic, including the leaf uplink.
- The Leaf also pauses all traffic from the Spine.
- The Spine pauses all traffic from other Leaf switches.
- Other Leaf switches pause all traffic from the TOR switches.
- The TOR switch pauses all traffic from the servers.
The solution to this problem is relatively straightforward: Microsoft designed two watchdogs—one on the server side and one on the switch side. On the server side, when the watchdog detects that a NIC is continuously sending pause frames, it prevents the NIC from doing so. On the switch side, a watchdog monitors each port; if a port continuously receives pause frames, it suspends lossless mode for that port and re-enables it after the pause frame storm has subsided for a certain period.
Slow-receiver Symptom
NICs are designed to store most of their data structures in main memory, keeping only a small cache on the NIC itself and using a Memory Translation Table (MTT) to store physical-to-virtual address mappings. The default MTT page size was too small, leading to frequent cache misses. This slowed down processing, causing buffers to fill beyond the PFC threshold and ultimately resulting in the NIC sending a large volume of PFC pause frames.
The solution is simple: increase the page size to reduce the probability of cache misses.
RDMA in Production
This section describes how Microsoft utilizes RDMA in production environments. It covers deployment strategies for configuration management and monitoring, as well as the tools developed to monitor PFC pause frame counts and latency.
The final section of this part presents several RDMA performance tests, showing that RDMA offers significant improvements in latency and throughput compared to TCP. However, it concludes by noting that RDMA is not a panacea that can simultaneously provide high throughput and low latency in all scenarios.
Experiences
The final chapter primarily discusses the real-world issues Microsoft encountered after deployment and their corresponding solutions. It also details their perspectives and concerns regarding RoCEv2 technology, while concluding with research exploring other RDMA technologies like InfiniBand and iWARP.
Conclusion
This paper introduces Microsoft's implementation of RDMA technology in data centers and how they resolved the issues they faced. In the "future works" section, it suggests topics for further exploration, such as low-latency inter-datacenter networks, deadlock resolution in various architectures, and methods to simultaneously achieve high bandwidth and low latency.
Reflections
I believe this paper is a must-read. Beyond understanding how RDMA technology functions within a network, Microsoft's troubleshooting experiences and methodologies offer valuable lessons for engineers involved in infrastructure design and deployment.
Copyright Notice: All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.

